Congressional Speech Research
2019 - 2020
This was a research project done during a Frshman-level class where we applied various text analysis metrics to US congressional speeches. These metrics include basic calculations such number of words and frequency of words in different categories as well as more advanced metrics such as the Coleman-Liau Index and sentiment analysis. My teammate and I decided that the most interesting way to examine this was to chart changes in these numerical metrics over time. After filtering, the dataset included 959,237 speeches over a timespan of 138 years.
This yielded many interesting results — the graphs were much less noisy than would normally be expected in data science. Our professor, Dr. Shamir, was impressed and worked with us after the course to publish the research. With his help, we were able to publish the work in Heliyon as “A Data Science Approach to 138 Years of Congressional Speeches” (doi:10.1016/j.heliyon.2020.e04417). It also received some media attention with commentators drawing conclusions of varying rigor from the work.
The actual metric calculations were done using Dr. Shamir’s own tool, UDAT. From that output, charts were generated using Python and matplotlib. I’d recommend reading the paper for more information on our methods and conclusions.
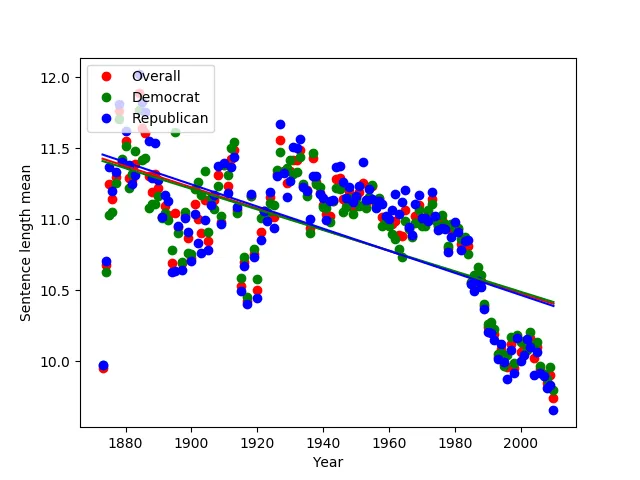
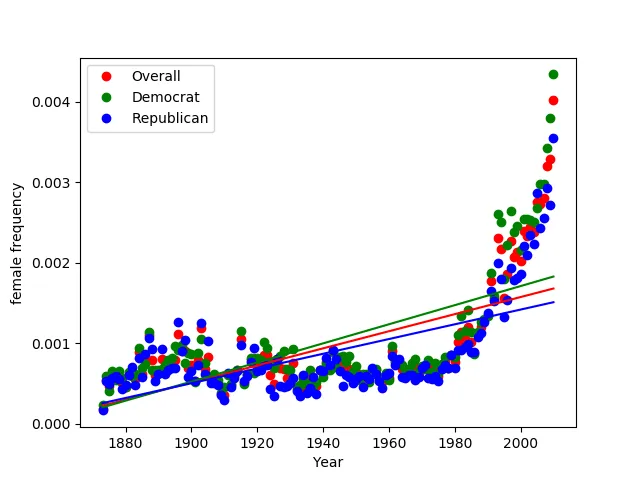
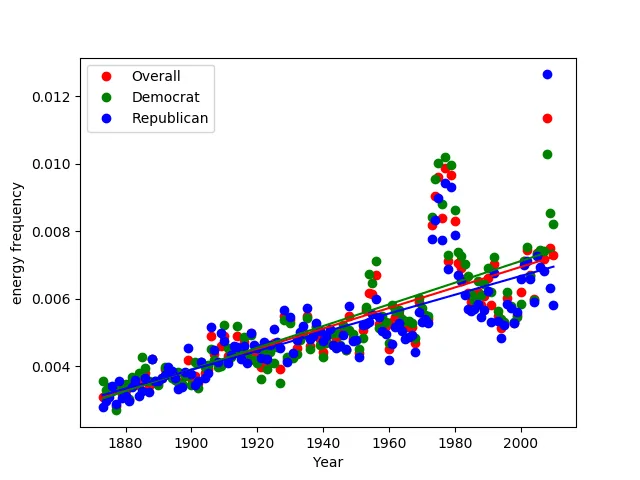
Here are a few of my favorite charts generated from this (pardon the poor choice of coloring):